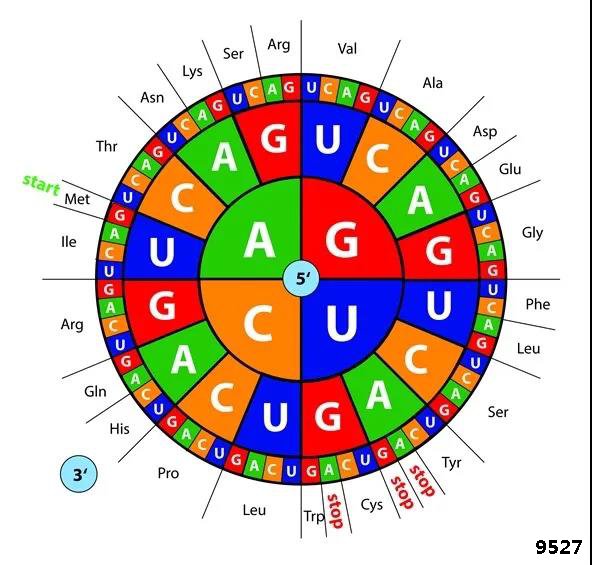
图1 通用的密码子表
事实上,在原核生物中,除了AUG外,GUG和UUG也可以作为起始密码子。以大肠杆菌为例,其基因组上使用AUG作为起始密码子的约占77%,以GUG为起始密码子的约占14%,以UUG为起始密码子的约占8%。当然还有更离谱的,如CUG。那么当GUG和UUG等作为起始密码子的时候,究竟编码什么氨基酸呢?是编码密码子表上(图1)所示的氨基酸,如GUG是缬氨酸(Val,V),UUG是亮氨酸(Leu,L),还是与AUG一样编码甲硫氨酸呢?
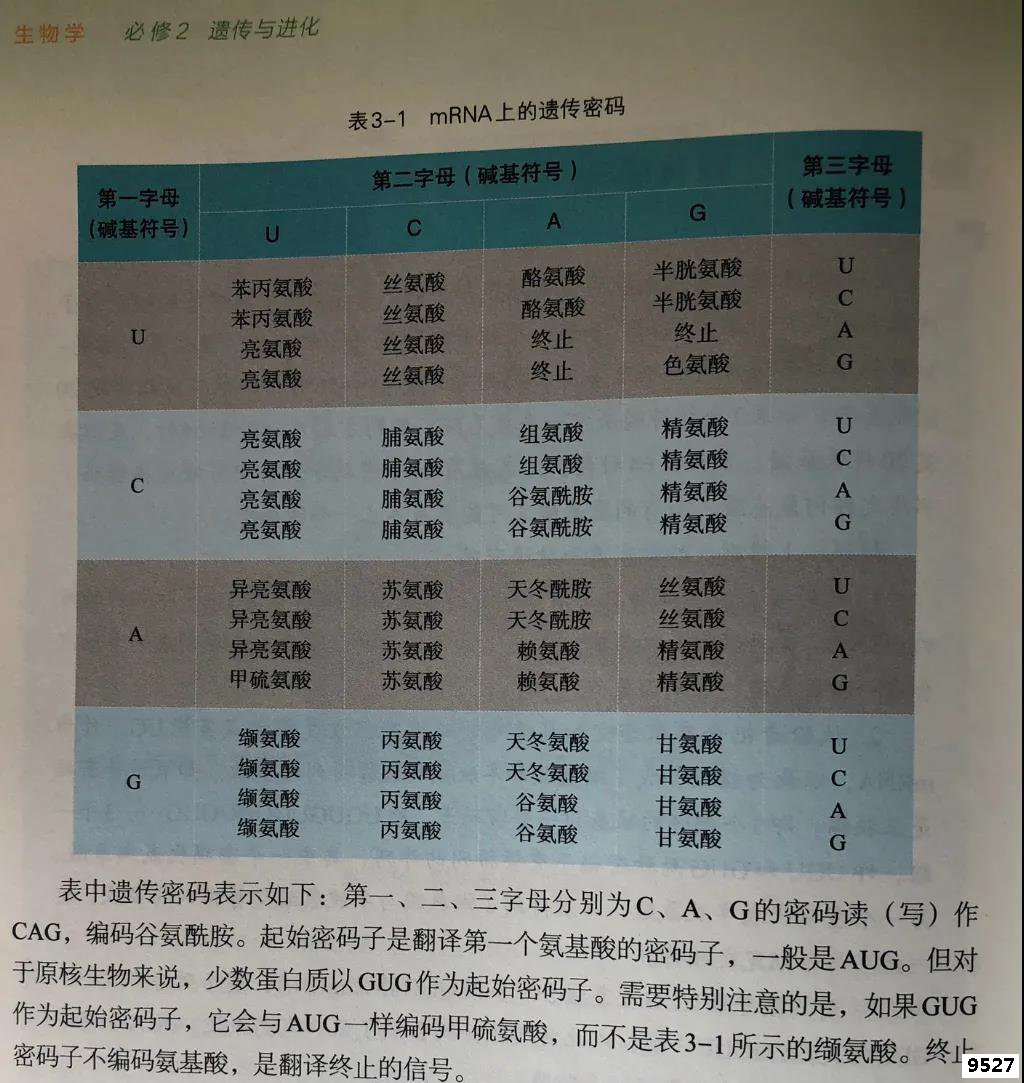
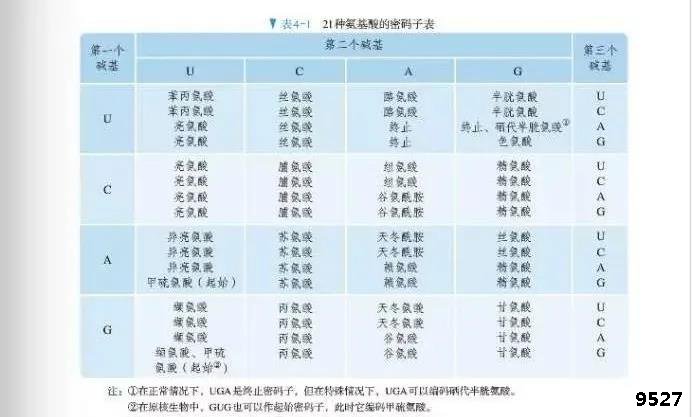
对于上述问题,就我所知,很多人想当然的会认为,肯定是遗传密码子表所示的氨基酸。殊不知,不管是哪一种密码子作为起始密码子,生物都会用统一的起始tRNA对其解码,而起始tRNA总是携带甲硫氨酸,因此都编码甲硫氨酸。当然,原核生物的中的细菌起始tRNA在携带甲硫氨酸以后,甲硫氨酸还要甲酰化修饰,故由起始密码子编码的是甲酰甲硫氨酸。记得在新版高中教材审定的时候,我建议在必修2(遗传与进化)这一册将密码子的地方,加上了相关的备注,以防老师在教学过程中讲错(图2)。这里有两个没有以AUG作为起始密码子的重要例子:一个是大肠杆菌乳糖(lac)操纵子编码阻遏蛋白的lacI基因,另一个是编码转乙酰酶lacA基因。它们分别以GUG和UUG作为起始密码子。那么为什么这些蛋白质基因在进化的过程中,起始密码子没有选择AUG呢?
对于这个问题,如果你知道控制一个基因转录起始的启动子有强有弱,而这可以用来作为控制基因产物量的一种方式,那么你同样可以理解选择AUG作为起始密码子和不用AUG作为起始密码子,也可以控制不同蛋白质翻译的量。对于细胞大量需要的蛋白质,用强启动子来启动转录更合适,因为这样可以转录出更多的mRNA,反之,对于细胞少量需要的蛋白质,用弱启动子更合适。按照这样的思路,细胞大量需要的蛋白质使用AUG作为起始密码子更合适,因为它更容易被起始tRNA上的反密码子(CAU)识别,因此AUG可视为“强起始密码子”,而细胞少量需要的蛋白质不用AUG作为起始密码子更合适,因为它不容易被起始tRNA上的反密码子识别,因此AUG以外的起始密码子可视为“弱起始密码子”。那么对于那些不用AUG作为起始密码子的蛋白质来说,如果强行将它们的起始密码子改造成AUG的话,它们还能正常翻译吗?
对于此问题,要看改造成AUG以后还能不能被起始tRNA识别!显然是可以被识别的,而且会变得更容易识别。因此,对于起始密码子改造成AUG的蛋白质来说,不仅照样翻译,而且翻译的效率会增加!因为它们原来先天不足的“弱起始密码子”变成了“强起始密码子”!
以上所说的起始密码子的例外是针对原核生物的,那么真核生物有任何例外吗?
事实上,真核生物的线粒体翻译系统就有例外,例如人类线粒体翻译系统使用AUA和AUU作为起始密码子,当然它们由线粒体内的起始tRNA对其解码,编码的也是甲酰甲硫氨酸。除此之外,还有什么其他例外吗?
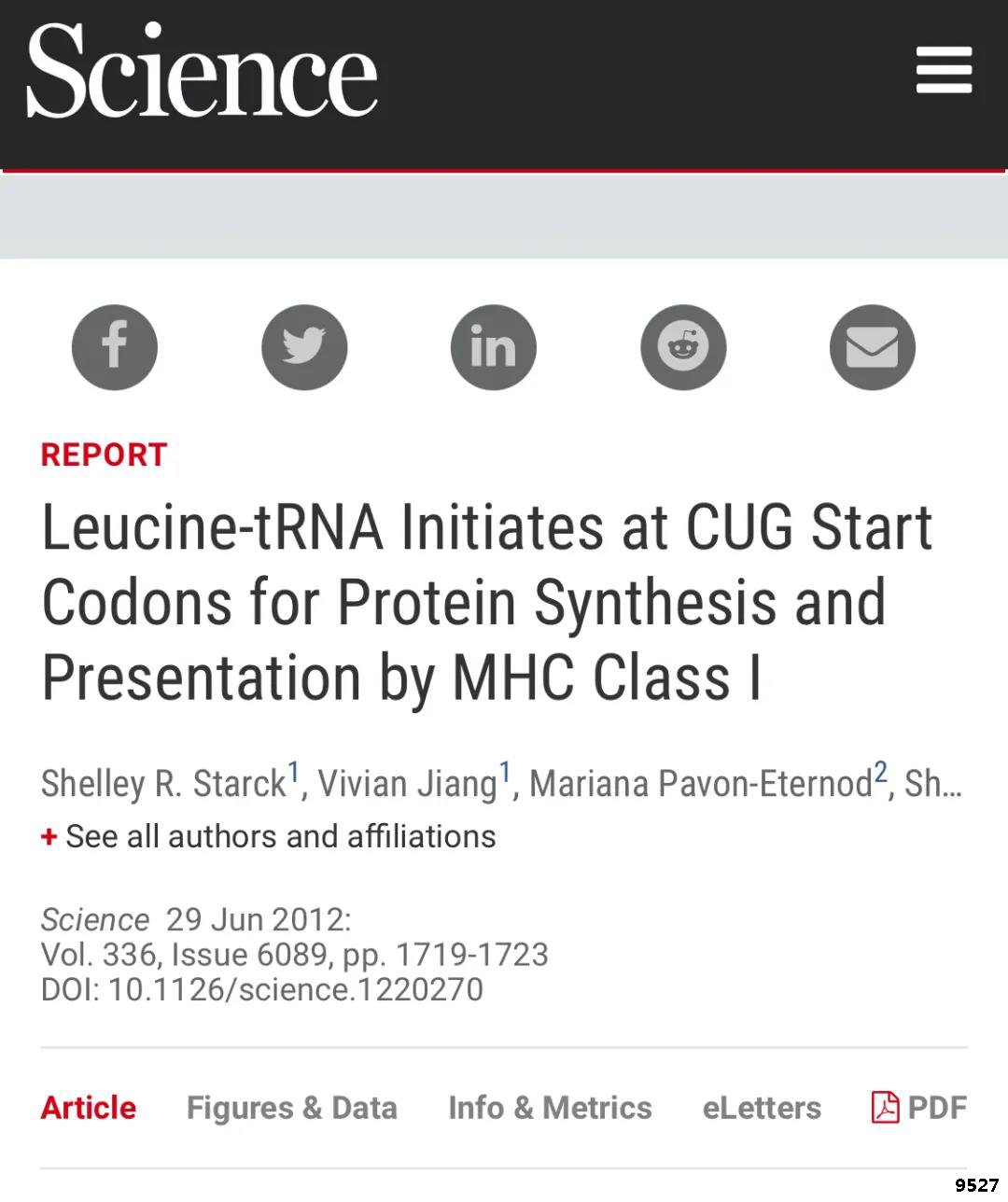
我的回答是有的!而且这个例外更加不可思议。事实上早在2012年6月,Science上有一篇题为“Leucine-tRNA Initiates at CUG Start Codons for Protein Synthesis and Presentation by MHC Class I”的研究论文。该论文报道:哺乳动物体通过细胞毒性T细胞进行有效的免疫监视,需要新合成的多肽才能通过主要的组织相容性复合体(MHC)I类分子呈递。而这些多肽不仅通过常规的AUG起始,而且还可以通过隐秘的CUG起始翻译。但如果使用CUG作为起始密码子,细胞会在起始因子2A(eIF2A)的帮助下使用亮氨酰tRNA(Leu-tRNA)来启动CUG起始密码子的翻译,而不是起始tRNA,这样翻译出来的就是密码子表所示的亮氨酸。
没想到有关起始密码子会有这么多的例外,我相信将来科学家还会发现更多的例外!

 网站首页
网站首页 必修一
必修一 必修二
必修二 选修一
选修一 选修二
选修二 选修三
选修三 高考竞赛
高考竞赛 教材汇总
教材汇总